In 1965, Gordon Moore predicted that engineers would be able to double the number of components on a microchip every two years. Known as Moore’s law, his prediction has come true – processors are continuing to become faster each year while the components are becoming smaller and smaller. In the footprint of the original ENIAC computer, we can today fit thousands of CPUs that offer a trillion more computes per seconds at a fraction of the cost. This continued trend is allowing server manufactures to shrink the footprint of the typical x86 blade server allowing more I/O expansion, more CPUs and more memory. Will this continued trend allow blade servers to gain market share, or could it possibly be the end of rack servers? My vision of the next generation data center could answer that question.
Before I begin, I want to emphasize that although I work for Dell, these ideas that I’ve come up with through my experience in the blade server market and from discussions with industry peers. They are my personal visions and do not reflect those of Dell nor are the ideas mentioned below limited to Dell products and technology.
The First Evolution of the Blade Server – Less I/O Expansion
Last November I wrote an article of my first vision of “The Blade Server of the Future” on CRN.com. In the article, I described two future evolutions of the blade server. The first was the integration of a shared storage environment (below). While the image depicts the HP BladeSystem C7000 modified with storage, my idea stems from the increase of onboard NICs driving a lot of the individual blade traffic. With 10Gb / CNA technologies being introduced as a standard offering, and with 40Gb Ethernet around the corner, the additional mezzanine cards and I/O expansion found on today’s blade server technology may not be required in the near future. The space freed up from the removal of the un-needed I/O bays could be used for something like an integrated storage area network, or perhaps for PCI expansion.

The Next Evolution of the Blade Server – External I/O Expansion
PCI expansion is another possible evolution within the blade server market. As CPUs continue to shrink, the internal real estate of blade servers increase, allowing for more memory expansion. However, as more memory is added, less room for I/O cards is available. While I mention that additional I/O may not be needed on blade servers with the standardization of large onboard Ethernet NICs, the reality is that as you cram more into a blade server, the more I/O will be required. I believe we’ll see external I/O expansion become standard in future evolutions of blade servers. Users of RISC technologies will be quick to identify that external I/O is nothing new and in fact, even in the x86 space has been an option through Xsigo.com however my vision is that the external capability would be an industry standard like USB or HDMI. While the idea of a standardized external I/O capability like shown in the image below is probably more of a dream than a reality, it leads to my long term vision of where blade servers will eventually evolve to.
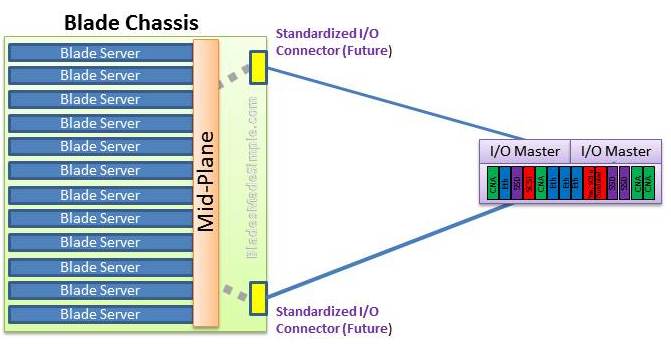
The Future of the Blade Server – Modular Everything
Blade servers rely on connectivity to the outside world through a mid-plane and I/O modules. They are containerized within the chassis that houses them allowing them to be an ecosystem for compute resources. What if we took the idea of how the blades connect to the blade chassis and extended it to an entire rack? Imagine having a shelf of blade servers that docked directly to a rack midplane (aka a “rackplane”). In fact, anything could be designed with this connectivity: storage trays, PCIe trays, power trays. What ever technology you need, be it compute power, storage or I/O could be added as needed. The beauty of this design is that the compute nodes could communicate with the storage nodes at “line speed” without the need for point-to-point cabling because they are all tied into the “rackplane”. Here’s what I think it would look like:

On the front side of the modular rack, a user would have the option to plug in whatever is needed. For servers, I envision half-size blade servers housed in a 1 or 2U shelf. The shelf could hold any number of servers, but I would expect that a shelf of 8 – 12 servers would be ideal. Keep in mind, in this vision, all we need are CPUs and memory inside of a “blade server” so the physical footprint of the future blade server could be the size of today’s full-length PCIe card. Each of the shelves, whether they are servers, storage or compute, would have docking connectors similar to what we see on today’s blade servers but on a much larger scale. On the back side of the modular rack, you would have the option to add in battery protection (UPS), cooling and of course, I/O connectivity to your data center core fabrics.
One of the most obvious disadvantages of this design is that if you had a problem with your “RackPlane”, it would take a lot of resources off line. While that would be the case, I would expect that the design would have multiple rackplanes in place that would be serviceable. Of course, if the racks were stacked side-by-side with other racks, that could pose a problem – but hey, I’m just envisioning the future, I’m not designing it…
What are your thoughts on this? Am I totally crazy, or do you think we could see this in the next 10 years? I’d love your thoughts, comments or arguments. Thanks for reading.
Kevin Houston is the founder and Editor-in-Chief of BladesMadeSimple.com. He has over 14 plus years of experience in the x86 server marketplace. Since 1997 Kevin has worked at several resellers in the Atlanta area, and has a vast array of competitive x86 server knowledge and certifications as well as an in-depth understanding of VMware and Citrix virtualization. Kevin works for Dell as a Server Sales Engineer covering the Global 500 market.
Kevin,
Great blog I love the thought experiement. After reading through this twice I think you may have just invented rack-mount servers.
Joe
Kevin,
Great blog I enjoyed the thought experiment. After rereading it I believe you may have just invented rack-mount servers!
Joe
Pingback: Kevin Houston
Pingback: Sarah Vela
Pingback: Dennis Smith ✔
Pingback: Andrew McMorris
Pingback: ulfrasmussen
Pingback: Ulf Rasmussen
Rackplane looks more like ATCA to me than rack-mounts. Or maybe a mainframe.
Clever idea, though I have two objections:
1) It’s *too* flexible. The rack midplane would have to be high-speed, low-latency, and resiliant. It would need to allow any device to go in any bay. Those kinds of cross-connects exist (e.g. in a Superdome, Fujitsu M-series, etc), but they’d be expensive and over-kill for most users.
2) I don’t like the idea of compute nodes being just “processor plus memory”. If you start adding flash storage as an ‘accelerator’ accompanying memory (like what was mentioned for Dell PowerEdge 12th gen at DellWorld), then the “memory” part might be something drastically different (and bigger) than a handful of DIMMs. Alternatively, maybe future servers will physically seperate compute cores from main memory, so maybe the two don’t always belong together.
Pingback: Joe Onisick
Pingback: Dell OEM Solutions
Pingback: Kevin Houston
Pingback: Daniel Bowers
Pingback: Mallory Blair
Pingback: korematic
Ya know… HP is not too far off from this actually. If you took the backplane architecture of the big 3Par, added some physical compatibility to plug in compute, and whisk in some secret sauce to manage it all… maybe?
The question is: would it sell?
I wouldn’t buy it. It’s too big.
Actually its more like the SuperDome 2 architecture rather than 3par, you need a crossbar rather than a meshed architecture to make scalability work to the level this is aiming at. You need to be able to “partition”resources off at a physical layer.
That second diagram is the original SuperDome circa 2000. Only difference is that its still assuming CPU and memory live on the same blade, take it one step up and assume memory, CPU, storage (actually with things like memristor or PCM the memory AND storage could be the same thing) and I/O are seperate bladed modules all linked by a common interconnect and then throw in the ability to start zoning/partitioning the communication between them and you have the true converged architecture. Plus you’ve just eliminated the need for a hypervisor.
Now have a look around at which vendors could actually execute on that …………..
Pingback: Blades are Not the Future — Define The Cloud
Pingback: Louis Göhl
Dear Kevin,
first thank you for that clear and simple illustration and language you are using through out your blog. It is a pleasure.
I totally agree with you in terms that the future should look like this. I do not understand, why DELL, IBM and HP not drive that kind of development faster or – let’s say it better – why they don’t relaese it (sure they all have already working prototypes of stuff like this). Not only the user would get greater integration and simplification of his datacenter. But the vendor would tie the customer even tighter to his brand, since all components are somehow backplaned which virtually locks the buyer within the particular brand.
I also dear of greater SAN integration within baldechassis offering wider storage capabilities as IBM BC-S..;)
Thanks and best wishes from Munich
Jew
Pingback: poseydonn
Pingback: Okechukwu Nwoke
From my perspective we have to look more from a mathematical and physical and chemical aspect.
At the momen you have 4 core elements. CPU, Memory, Network and Disk.
Disk is at the moment the slowest component.
This has changed with satadimm.
http://www.vikingmodular.com/products/ssd/satae/satadimm.html
The next big thing comes with Reram, FERAM and Memresistor in 2013. This are 100 to 1000 faster than ssd.
http://www.nvnews.net/vbulletin/archive/index.php/t-167269.html
HP, Hynix, Samsung and others are now developing Flash NAND successor called
ReRAM that are 10 times faster than 22nm NAND, able to double the memory space
cheaper than NAND, use half power consumption than NAND and can write more than
1 trillion write cycles per sector. SSDs with ReRAM will launch in 2013, it will
replace both Flash NAND SSDs and HDDs as ReRAM now far more reliable than either
MLC and SLC Flash NAND and it finally can be use for very heavy users.
HP’s memristor reality in 2013, can revolutionize SSD and RAM market
http://www.nordichardware.com/news/83-science/44388-hps-memristor-reality-in-2013-can-revolutionize-ssd-and-ram-market.html
http://forums.vr-zone.com/news-around-the-web/904387-elpida-sharp-reram-10-000-times-faster-than-nand-flash-memory-2013-a.html
The ReRAM or resistive random access memory chip consumes less power and is
capable of writing data 10,000 times faster than NAND flash memory
So this the means if the disk is elminated , we will have 3 elements left. So it is 3! (factorial).
RAM and ReRAM will may be use the same Dimmslot.
As you can see with the viking satadimm you can build extrem small micro servers.
So than the dimm is the biggest component in the computer.
The network will than be the slowest component.
http://www.usenix.org/event/hotos11/tech/slides/rumble.pdf (Page 6 Nic is moving into the cpu).
http://www.scs.stanford.edu/~rumble/papers/latency_hotos11.pdf
Pingback: Travis Haasch
Well, IBM just launched PureSystems. The future is right on the corner..
Pingback: Why Blade Servers Will be the Core of Future Data Centers | Yusuf Mangera
Pingback: Intel’s Advancements Lead to the Future of the Data Center – Making blade servers simple
Pingback: Are Blade Servers Dead, or the Future of the DataCenter? » Blades Made Simple